Busca Semântica: como ensinar máquinas a entender intenção (não só palavras)
Há uns anos, se você me perguntasse como funciona busca em um sistema sério, eu responderia em três palavras: índice invertido, BM25, fim. Era o estado da arte, era o que rodava em todo lugar, e era o que eu sabia o suficiente pra ensinar.
Hoje, depois de colocar busca semântica em produção em cima de quase um milhão de documentos, eu mudaria a resposta. Não porque BM25 ficou ruim — pelo contrário, ele continua sendo a base de quase todo sistema de busca no mundo. Mudaria porque BM25 sozinho está deixando muito valor na mesa. E o que preenche esse vazio é uma ideia que parece mágica, até você entender o que está acontecendo por baixo.
Esse é o primeiro post de uma série sobre busca moderna. Aqui a gente trata só de busca semântica — o quê, o porquê, o como. No próximo, vamos somar BM25 com vetorial em busca híbrida. No terceiro, fechamos com reranking, a cereja que separa busca boa de busca excelente. Mas antes a gente precisa entender o problema base.
O problema que ninguém nota
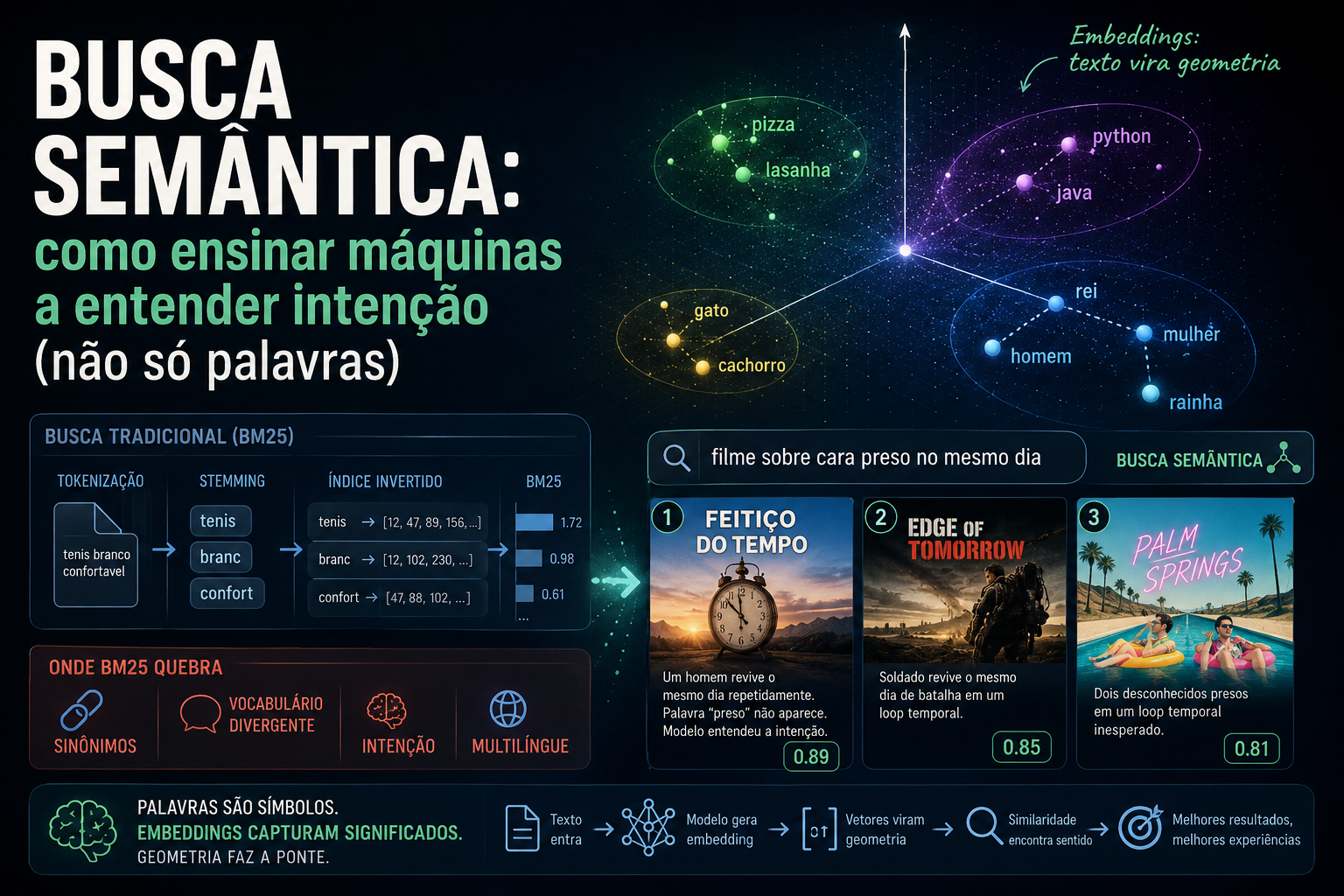
Imagine que você está construindo um catálogo de filmes. Pode ser um Letterboxd, um IMDB, um app interno. Um usuário chega e digita:
“filme sobre cara preso no mesmo dia”
Você sabe o que ele quer. Eu sei o que ele quer. Qualquer pessoa que viu Feitiço do Tempo sabe o que ele quer. O problema é que seu banco de dados não sabe.
Se você está usando o que 99% dos sistemas usam — busca textual baseada em índice invertido — o banco vai pegar essa query, procurar pelas palavras literais (“cara”, “preso”, “mesmo”, “dia”) e te entregar:
- O Especialista (tem “preso” no roteiro)
- Os Detentos (tem “preso” no título)
- Qualquer documentário sobre o sistema penitenciário
Resultado: o usuário não encontra Feitiço do Tempo, fecha o app, abre o Google e digita exatamente a mesma frase. E o Google encontra. Por quê? Porque o Google não está fazendo
LIKE '%preso%'.
A diferença entre “busca que funciona” e “busca que frustra o usuário” não está no banco que você usa, nem na quantidade de servidores. Está em entender que palavras não são significados, e que existem ferramentas pra preencher esse abismo.
Como a máquina vê texto: BM25 e amigos
Antes de falar do bonito, vamos entender o que está rodando hoje em quase todo lugar.
Quando você manda "tenis branco confortavel" pro Elasticsearch (ou OpenSearch, ou Solr — todos da mesma família), três coisas acontecem em sequência. Primeiro, tokenização: a string é quebrada em palavras individuais. Segundo, stemming: sufixos são cortados pra reduzir variações morfológicas. “tenis”, “branco”, “confortavel” viram “tenis”, “branc”, “confort”. Terceiro, isso bate contra o índice invertido: uma estrutura que, pra cada token, guarda a lista de documentos onde aquele token aparece.
tenis -> [12, 47, 89, 156, ...]
branc -> [12, 102, 230, ...]
confort -> [47, 88, 102, ...]
Documento 12 aparece em duas listas. Documento 47 também. Documento 88, em uma só. Quanto mais listas o documento aparece, mais provável ele ser relevante. Mas isso é só o começo.
O que ordena os resultados é o BM25 — Best Match 25, a vigésima quinta iteração de uma família de algoritmos que começou nos anos 70. É o default do Elasticsearch, do OpenSearch e do Solr. Se você usa busca textual em algum lugar, BM25 é quem está pontuando.
A fórmula parece intimidante, mas tem três ideias só:
Term Frequency (TF): quantas vezes o token aparece no documento. Mais vezes, mais relevante. Mas não linear — se aparecer 50 vezes, não é 50× melhor que aparecer 1 vez. A fórmula satura.
Inverse Document Frequency (IDF): termos raros valem mais. A palavra “tênis” aparece em 2% do seu catálogo de moda — peso alto. A palavra “de” aparece em 100% dos documentos — peso quase zero. Faz sentido: se você procurou “tênis branco”, acertar “tênis” me diz muito mais sobre relevância do que acertar “branco”.
Normalização por tamanho: documento curto que contém o termo é mais relevante que documento longo que contém o termo, porque a chance de ser exatamente sobre aquilo é maior. Sem isso, um manual técnico de 5000 palavras ganharia de uma descrição curta só por volume.
BM25 mistura essas três coisas e gera um score. Documento com score maior vai pro topo. É elegante, escala bem, e funciona razoavelmente em domínio fechado. Mas tem quatro grandes pontos cegos.
Onde BM25 quebra
Sinônimos. Usuário busca “celular”, catálogo tem “smartphone”. Zero match. Você pode até resolver com dicionário manual de sinônimos, mas vai manter isso pra português, inglês, gírias regionais e jargão de cada nicho? Boa sorte.
Vocabulário. Usuário busca “roupa fresquinha pra usar no calor”. Catálogo tem “blusa de linho manga curta”. Mesma intenção, zero palavras em comum. BM25 não devolve nada.
Intenção. Usuário busca “filme bom pra ver com a namorada”. O que isso significa? BM25 vai bater em “filme”, “bom” e “namorada” e te entregar resultado aleatório.
Multilíngue. Você indexou em português, o usuário busca em inglês. Mesmo conteúdo, idiomas diferentes, BM25 não tem como saber que é a mesma coisa.
O problema, no fundo, é o mesmo: BM25 olha pra superfície do texto, não pro significado. Ele é uma ferramenta de coincidência de tokens, não de compreensão.
É aí que entra a parte interessante.
Embeddings: texto vira geometria
A definição mais simples e mais poderosa que existe:
Um embedding é um vetor denso de N números que representa o significado de um pedaço de texto.
Você manda a palavra “pizza” pro modelo de embedding. Ele te devolve uma lista de — digamos — 1024 números entre -1 e 1:
[0.21, -0.05, 0.78, 0.13, -0.42, ..., 0.09]
Manda “lasanha”. Ele devolve outra lista de 1024 números:
[0.19, -0.08, 0.81, 0.10, -0.40, ..., 0.07]
A mágica é que essas duas listas vão ser quase idênticas. Não porque o modelo viu “pizza” e “lasanha” juntas — embora isso tenha ajudado no treinamento — mas porque ele aprendeu que ambas vivem no mesmo bairro semântico: comida italiana, prato principal, base de massa, contexto de jantar.
Agora manda “Python”. O vetor vai ser muito diferente. Porque Python é linguagem de programação, é tecnologia, é outro contexto inteiro. O vetor de “Java” vai ser parecido com o de “Python”, porque ambos são linguagens. Pizza e lasanha ficam juntas num canto, Python e Java ficam juntos noutro canto, gato e cachorro ficam juntos num terceiro canto.
A distância entre dois vetores vira uma medida de similaridade semântica. Esse é o pulo do gato. Você converteu texto — que é simbólico, discreto, difícil de comparar — em geometria. E geometria a gente sabe medir.
Na prática, gerar um embedding parece com isso:
from openai import OpenAI
client = OpenAI()
response = client.embeddings.create(
input="pizza margherita",
model="text-embedding-3-small"
)
vector = response.data[0].embedding # lista de 1536 floats
Pronto. Texto entrou, geometria saiu.
Álgebra com significados
Pra deixar isso menos abstrato: como esses vetores carregam significado de verdade, você pode fazer conta com eles. Conta de verdade. O experimento clássico, do paper de Mikolov de 2013:
vetor("rei") - vetor("homem") + vetor("mulher") ≈ vetor("rainha")
O modelo aprendeu, sem ninguém ensinar explicitamente, que existe um eixo de masculinidade-feminilidade no espaço vetorial. Outro:
vetor("Paris") - vetor("França") + vetor("Itália") ≈ vetor("Roma")
Capital de país, como conceito, virou uma direção no espaço. Você pode subtrair “França” pra remover o componente “país específico”, aí somar “Itália” pra colocar de volta. O resultado aterrissa perto da capital italiana.
Isso não é matemática teórica bonita. É literalmente o que acontece dentro do modelo. Por isso busca semântica funciona: o modelo aprendeu estrutura do mundo, e você está fazendo geometria em cima dessa estrutura.
De onde vêm esses números
Modelos de embedding são redes neurais treinadas em quantidades absurdas de texto pra aprender essas representações. As famílias principais hoje:
APIs comerciais. OpenAI (text-embedding-3-small, text-embedding-3-large), Cohere (embed-v3, forte em multilíngue), Voyage AI. Caros, mas qualidade no topo do leaderboard, sem você precisar manter infra.
Open-source de ponta. BGE (da BAAI), E5 (da Microsoft), GTE (da Alibaba). Você roda na sua GPU, zero custo de API, zero vendor lock-in. BGE-M3 e BGE-large multilingual competem bem com OpenAI em vários benchmarks.
Base clássica. Sentence-Transformers — a biblioteca que popularizou tudo isso. Modelos menores, mais simples, ótimos pra prototipar.
Como escolher? Vai no MTEB — o Massive Text Embedding Benchmark, leaderboard público de referência. Escolhe um modelo na sua faixa de custo e tamanho, e testa no seu domínio. Modelo bom em inglês pode ser ruim em PT-BR. Modelo bom em texto curto pode ser ruim em documento longo. Modelo bom em domínio geral pode ser ruim em vocabulário jurídico, médico, técnico. Sempre meça.
Como comparar dois vetores
Você tem o vetor da query, tem os vetores dos documentos. Como comparar? Três opções, em ordem do que você provavelmente vai usar.
Similaridade do cosseno mede o ângulo entre os vetores, ignorando magnitude. Vai de -1 a 1 (na prática, em texto, fica entre 0 e 1). É o default na esmagadora maioria dos casos, porque o significado mora na direção, não no tamanho do vetor.
Dot product é o produto escalar. Importa direção e magnitude. Se seus vetores são normalizados — e a maioria dos modelos modernos retorna normalizados — dot product é matematicamente equivalente ao cosseno e mais barato de computar. Use isso pra otimizar.
Distância euclidiana é a reta entre dois pontos. Funciona, mas é menos comum em texto. Aparece mais em embeddings de imagem.
Regra prática: comece com cosseno, troque pra dot product quando for otimizar.
kNN, ANN e o problema de escala
Como achar os documentos mais parecidos com a query? O algoritmo conceitual é k-Nearest Neighbors (kNN). Quatro passos: pega a query, gera o embedding, mede a distância pra cada documento do catálogo, ordena e retorna os top K.
Funciona perfeitamente em mil documentos. Em um milhão, calcular distância contra cada um é O(n), inviável em tempo real.
A solução é o ANN — Approximate Nearest Neighbors. Você abre mão de um pouco de precisão pra ganhar ordens de magnitude em velocidade. Ao invés de comparar com todos, compara com um subconjunto inteligentemente escolhido.
O algoritmo mais popular hoje é o HNSW — Hierarchical Navigable Small World. Funciona como um mapa do mundo com vários níveis de zoom: você começa no nível mais alto, navega rapidamente até chegar perto da resposta, aí desce pra níveis mais detalhados e refina. De O(n) você cai pra O(log n). É o que o Elasticsearch usa, o que o pgvector usa, o que praticamente todos os bancos vetoriais usam por baixo.
Em produção, recall de 95-98% é fácil de atingir com HNSW bem configurado, e a latência fica na casa dos milissegundos.
Onde rodar isso
O ecossistema explodiu nos últimos anos. Eu divido em duas famílias.
Bancos vetoriais dedicados: Pinecone (SaaS), Weaviate, Qdrant, Milvus, Chroma. Nasceram pra isso. Geralmente entregam melhor performance e features mais maduras pra busca vetorial. A desvantagem é que é mais um banco pra manter.
Bancos que ganharam suporte vetorial: Elasticsearch e OpenSearch (já tinham busca textual madura, ganharam vetorial); PostgreSQL com a extensão pgvector; Redis; MongoDB. A vantagem aqui é reaproveitar stack que você já tem. A desvantagem é que features e performance às vezes não são tão polidas quanto nos dedicados.
Como decidir? Se você já tem Elasticsearch rodando em produção, comece adicionando vetorial nele. Não troque de banco por causa de uma feature nova. Se está começando do zero e quer simplicidade, Qdrant e Weaviate são ótimos. Se é Postgres-first e volume moderado, pgvector resolve. Não tem resposta única — tem trade-off.
O exemplo dos filmes, agora com semântica
Lembra da query do começo? “filme sobre cara preso no mesmo dia”. Antes, com BM25, ela retornava O Especialista e Os Detentos pelo “preso” literal. Agora, com busca vetorial:
| Posição | Filme | Score |
|---|---|---|
| 1 | Feitiço do Tempo | 0.89 |
| 2 | Edge of Tomorrow | 0.85 |
| 3 | Palm Springs | 0.81 |
Olha o detalhe importante: a sinopse de Feitiço do Tempo diz “homem revive o mesmo dia repetidamente”. A palavra “preso” não aparece. Mas o modelo entendeu que loop temporal é uma forma de estar preso no tempo. Palm Springs é um filme indie que muita gente nunca viu — mas o modelo conhece, porque treinou em descrições da internet inteira.
Mesma query. Resultados completamente diferentes. Sem dicionário de sinônimos. Sem regras manuais. O modelo só fez geometria.
Onde a busca vetorial também quebra
Antes que você saia daqui só com brilho no olho — vetorial também tem buracos sérios.
Identificadores exatos. Usuário busca SKU-A4729. Busca vetorial vai retornar coisas semanticamente parecidas, que não é o que ele quer. Pra SKU, código de produto, ID, número de pedido — você precisa de match exato, não similaridade.
Negações. “Sapato sem cadarço” pode te retornar sapato com cadarço, porque o conceito “cadarço” está fortemente representado no vetor da query. Modelos modernos lidam melhor com isso, mas continua frágil.
Queries muito curtas ou ambíguas. “java” — é a linguagem, a ilha ou o café? BM25 também sofre, mas vetorial não resolve magicamente.
Custo. Gerar embedding pra cada documento custa. Storage de vetor custa (1024 dimensões × 4 bytes × N documentos). Reindexar quando você muda de modelo custa. Latência de gerar embedding da query a cada busca também custa.
Quando você junta os pontos cegos — exatidão, queries curtas, custo — fica claro: substituir BM25 por vetorial é trocar um conjunto de problemas por outro.
A solução é somar, não substituir
A boa notícia é que esses dois mundos têm pontos cegos complementares. BM25 é forte exatamente onde vetorial é fraco: match exato, SKU, palavras-chave específicas. Vetorial é forte exatamente onde BM25 é fraco: significado, intenção, vocabulário divergente.
Quando você junta, o que uma falha a outra cobre.
É disso que se trata o próximo post: busca híbrida. Como rodar BM25 e vetorial em paralelo, como fundir os rankings sem cair na armadilha óbvia de pesar score com score, e por que essa é a arquitetura que entrega o melhor resultado em produção desde o dia zero, sem ajuste manual de pesos.
Até lá, se você nunca brincou com embeddings, abre um notebook. Pega a API da OpenAI (ou roda o BGE local), embeda umas dezenas de frases do seu domínio, calcula cosseno entre elas e olha o que aparece junto. É a melhor forma de internalizar a ideia: ver com os próprios olhos que o modelo realmente entende.
Esse é o primeiro post de uma série sobre busca moderna. Próximo: busca híbrida com Reciprocal Rank Fusion. Se você está aplicando isso em algum contexto, me manda mensagem. Adoraria saber no que você está mexendo.
Comentários
Sem cadastro. Suporta markdown básico. Validamos com Cloudflare Turnstile pra evitar spam.